TL:DR
Logstash and beats are the ingesting part of the Elastic Stack. It can read data from a lot of sources, modify them and ingest them in an optimized way.
Beats are all in one datashippers to help teams adding common logs and metrics in Elastic in minutes.
Logstash is a lightweight ETL that make companies able to send and enrich information without modifying their application codes
Ingesting datas
The first step to benefit from all the power of Elasticsearch is to add data in it.
Most of the time consumed by developers in Elastic usage is spent adding data to Elasticsearch.
To speed up this key step, the Elastic company created Open Source tools to help all developers handle all use cases, from the most common ones to the most specific ones.
Elastic offer 3 possibilities to index your data:
- API – add data from you app calling RESTfull apis of Elasticsearch with POST and _bulk
- Beats data shippers to send easily logs and metrics
- Logstash to ingest from everywhere, normalize and enrich data before ingesting
Let’s learn how the ingesting tools from the Elastic Stack works.
Beats lightweight data shippers for Elasticsearch
Beats are defined as lightweight data shippers.
They are small binaries specialized to read and ship easily data for common use cases.
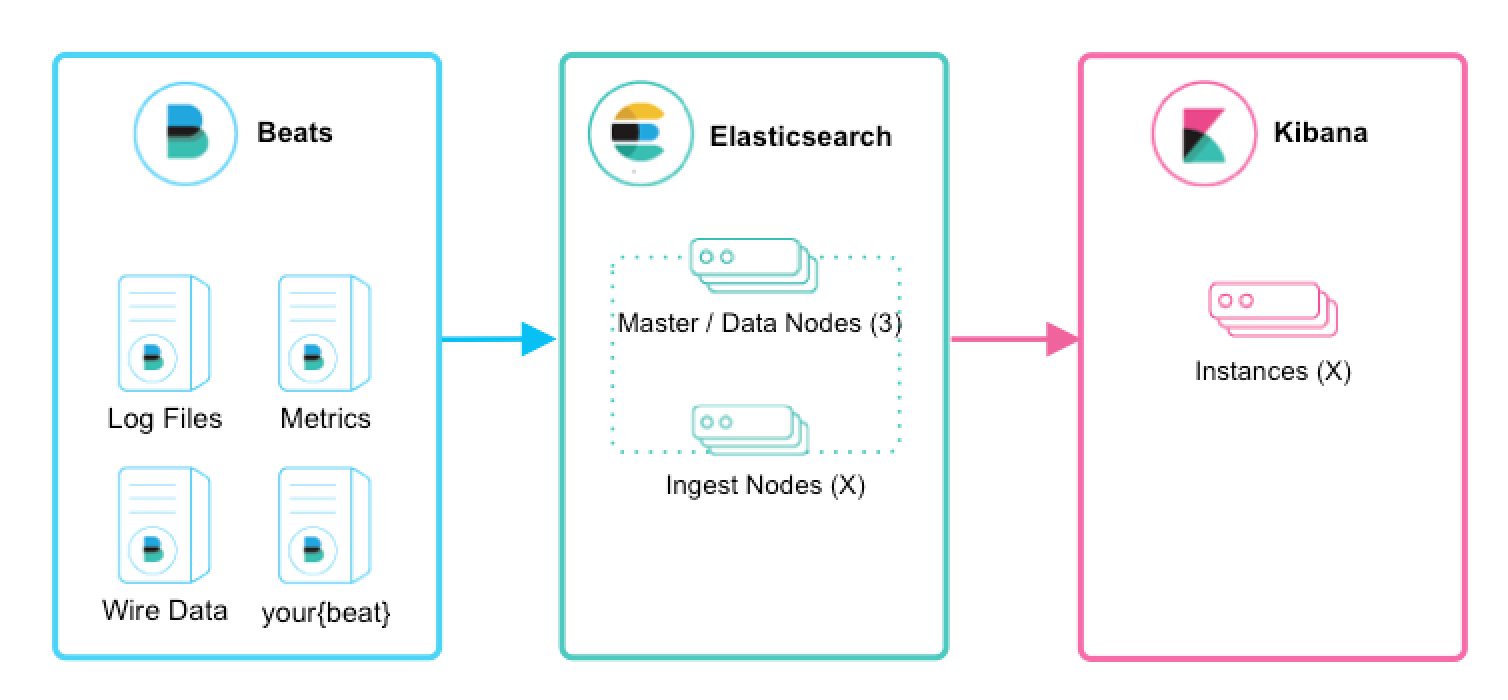
Several beats exist with bundle settings to handle automatically logs or metric datas.
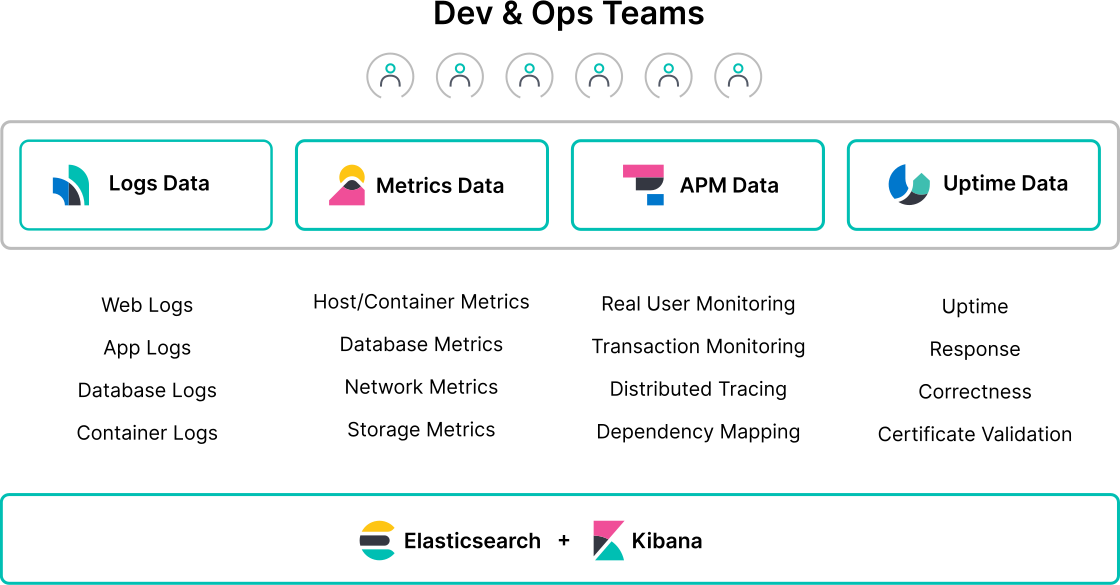
They also allow you to automatically create dashboards in Kibana and datas respect the ECS format out of the box.
Beats can be interfaced directly with Elasticsearch or to Logstash for complex use cases.
Logstash
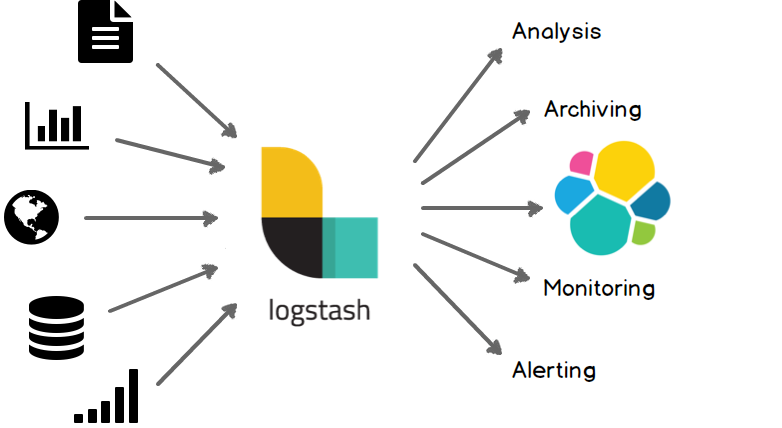
Logstash is an Extract, Transform and Load (ETL) tool.
It’s a really powerful tool to parse data from any source, normalizing, cleaning and enriching them, then load them anywhere.
A classical use case is reading data from several data sources, like SQL database, logs and CSV files, create pipelines to modify them and send them to Elasticsearch and / or other tools
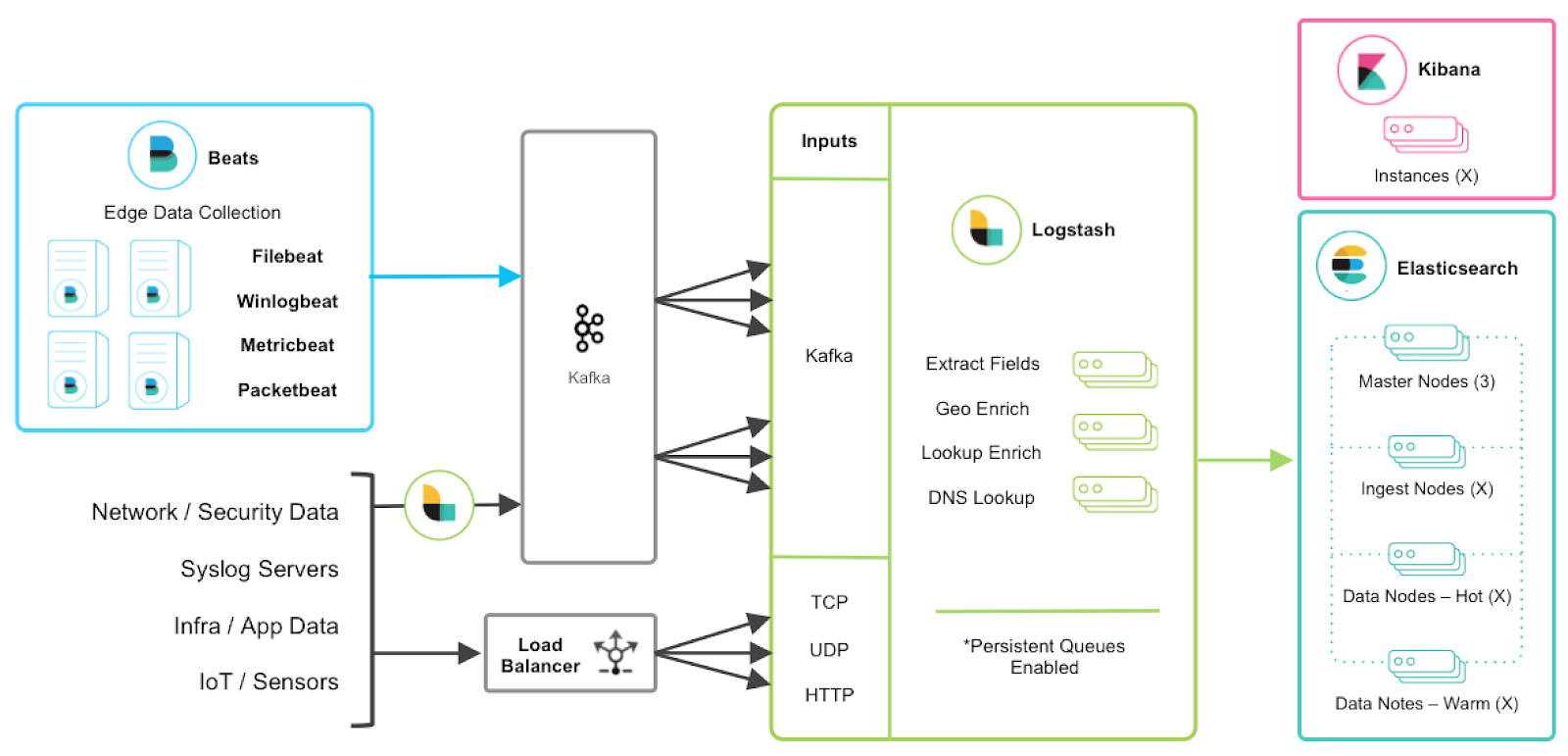
Discover In the schema below how a full ingestion pipeline can be designed to scale respond to a larger use case.
Spoon consulting is a certified partner of Elastic
As a certified partner of the Elastic company, Spoon Consulting offer a high level consulting for all kinds of companies.
Read more information on your personal use Elasticsearch use case on Spoon consulting’s posts
